Luke Dev Notes


One AGENTS.md for Multiple AI Coding Agents (Part 1)
AI coding tools have been arriving one after another. Cursor (2023), Claude Code (February 2025), Codex CLI / Codex coding agent (April-May 2025), and even Google Antigravity (November 2025, which has now become one of my primary tools) all bring their own configuration files, rule formats, and workflows. At first, I also wondered whether every new tool meant learning a new setup, and whether every tool needed its own project instruction file. I eventually changed the way I looked at the problem. The repo should be the stable entry point. The tools should adapt to the repo. If a project contains one clear, version-controlled set of working rules, then Cursor, Claude Code, Codex, or the next tool should be able to understand how the project is installed, built, tested, written, and committed.AI coding tools will change, but a repo's working rules should be maintained in one place.Note: in this article, Codex refers to the Codex CLI / Codex coding agent that OpenAI introduced in 2025, not the 2021 OpenAI Codex code generation model. More Tools, More Drift The worst situation for an AI coding agent is not that it cannot write code. It is that it follows an outdated project rule. This usually happens quietly. Maybe the project started with Cursor, so you created .cursor/rules. Later, you tried Claude Code and added CLAUDE.md. Then you tried Codex and added AGENTS.md. Each file made sense when it was created, but after a few months, they no longer say the same thing. For example:AGENTS.md says every commit needs a body CLAUDE.md still describes the old single-line commit style .cursor/rules contains an outdated test command skill instructions have been copied into several tool-specific foldersThis kind of drift is hard to fix with memory. People forget to update documentation, and an agent can only follow the files it reads. When the same repo gives different tools different rules, the development workflow becomes the thing that breaks. My direction is simple: keep one project instruction source in the repo. When a tool needs its own entry file, make that file an adapter. The Official Docs Point in the Same Direction After reading the official docs for Claude Code, Codex, and Cursor, I found that their file formats differ, but the architecture can still converge. Codex: Use AGENTS.md for Project Instructions Codex treats AGENTS.md as the main project instruction entry point. It is a good place for stable repo rules such as:project structure common commands coding conventions verification steps PR and commit expectationsCodex also supports a root AGENTS.md plus nested AGENTS.override.md files. If a subdirectory needs special rules, that directory can contain an override file, and the rules closer to the working directory take higher priority. This is a good fit for stable, repo-wide expectations. It is not where I would put a long task workflow, because task-specific details grow quickly and make the entry file harder to maintain. Claude Code: Import AGENTS.md From CLAUDE.md Claude Code reads CLAUDE.md by default. If the repo already has AGENTS.md, the official docs recommend importing it from CLAUDE.md: @AGENTS.mdThis detail matters. Writing only AGENTS.md inside CLAUDE.md may look like a hint to the model, but it is not the official import syntax. Using @AGENTS.md turns CLAUDE.md into a thin adapter. The actual project instructions still live in AGENTS.md. Cursor: Root AGENTS.md Is Enough for Simple Cases Cursor primarily recommends .cursor/rules, because rules can do more advanced things: always apply, attach by file path, or be requested by the agent. Cursor also supports root AGENTS.md as simple project instructions. For a repo that only needs one project-wide rule set, that is enough. If the project later needs different rules for src/content/posts/, src/components/, or infra/, then .cursor/rules can be added with a clear reason. My default choice is to let AGENTS.md carry the shared entry point first. Cursor rules can come in when I actually need path-scoped or trigger-specific behavior. Google Antigravity: Native Support for AGENTS.md Google's Antigravity (released in late 2025, and now a core part of my development suite) natively supports AGENTS.md in the project root. It reads this file upon startup to understand the repository's build, test, and command constraints. When we want to introduce complex, repeatable developer workflows, we can direct it to read the .skills/ directory from within AGENTS.md (e.g., for article polishing or git reviews), allowing a clean, unified rule structure to run seamlessly inside Antigravity's autonomous IDE environment. A Minimal Shared AGENTS.md Strategy AGENTS.md should answer one question: how does this repo expect work to be done? I keep it short and stable: # Agent Instructions## Repository Expectations- Follow the existing project structure and style before introducing new patterns. - Keep shared agent skills in `.skills/`. - Do not duplicate skill files under tool-specific directories.## Commands- Install dependencies: `npm install` - Start dev server: `npm run dev` - Build: `npm run build` - Type check: `npm run check`## Verification- Run `npm run build` after changing Astro, React, styling, or content rendering code. - Run `npm run check` after changing TypeScript or Astro components. - For documentation-only or skill-only changes, no build is required unless behavior changes.These rules are stable. They should not change just because I use Claude Code today and Codex tomorrow. Then the tool-specific files become adapters: AGENTS.md # the only project instruction source CLAUDE.md # @AGENTS.md .cursor/rules # add only when advanced Cursor rules are neededNow the repo has only one project instruction file to maintain. Claude Code imports it through CLAUDE.md. Cursor and Codex can read it directly.Tools can have their own adapters, but the rule source should not split.In the next post, I will use this blog repo as the concrete example: AGENTS.md as the stable entry point, .skills/ for task workflows, and one shared setup that Claude Code, Codex, and Cursor can all follow.One AGENTS.md for Multiple AI Coding Agents (Part 2)ReferencesOpenAI Codex: Custom instructions with AGENTS.md OpenAI Codex: Agent Skills Claude Code: Memory Claude Code: Skills Cursor: Rules Google Developers Blog: Build with Google Antigravity Google Antigravity Official Portal AGENTS.md Guide: Cross-Tool Rules for Antigravity AGENTS.md Official Standard OpenAI: Introducing Codex TechCrunch: Anysphere raises $8M from OpenAI to build an AI-powered IDE TechCrunch: Anthropic launches Claude Code research preview
Read More One AGENTS.md for Multiple AI Coding Agents (Part 2)
In the previous post, I summarized the common direction from the official docs: AGENTS.md can be the shared project instruction entry point for a repo.One AGENTS.md for Multiple AI Coding Agents (Part 1)This post uses my own blog repo as the concrete example. The goal is direct:maintain project instructions in one place maintain task workflows in one place keep tool-specific files as adapters check shared team rules into gitWith this shape, switching tools does not mean rewriting the repo rules. A new AI coding agent only needs to find the repo entry point before it can start understanding the project. The Final Repo Structure I ended up with this structure: AGENTS.md CLAUDE.md .skills/ README.md tech-blog-polish/ SKILL.md git-change-commit-review/ SKILL.mdAGENTS.md is the only project instruction source. It contains stable information every tool should know: commands, verification, project structure, and git workflow. CLAUDE.md contains one line: @AGENTS.mdThis lets Claude Code import AGENTS.md. CLAUDE.md no longer copies project rules, so it cannot drift away from the canonical file. For Cursor, I removed the old .cursor/rules/skills.mdc. That file repeated the same content as AGENTS.md. Since Cursor can read root AGENTS.md, this repo does not need .cursor/rules yet. AGENTS.md Is the Stable Entry Point The job of AGENTS.md is to tell an agent how work is done in this repo. I include rules like these: # Agent Instructions## Repository Expectations- Follow the existing project structure and style before introducing new patterns. - Keep shared agent skills in `.skills/`. - Do not duplicate skill files under tool-specific directories.## Commands- Install dependencies: `npm install` - Start dev server: `npm run dev` - Build: `npm run build` - Type check: `npm run check`## Verification- Run `npm run build` after changing Astro, React, styling, or content rendering code. - Run `npm run check` after changing TypeScript or Astro components. - For documentation-only or skill-only changes, no build is required unless behavior changes.These rules are not tied to one tool. Codex, Claude Code, and Cursor should all reach the same conclusion after reading them. Then I add a short project structure section: ## Project Structure- Blog posts live in `src/content/posts/`. - English posts live in `src/content/posts-en/`. - Shared agent skills live in `.skills/`. - Static assets live in `public/`.This looks ordinary, but it saves the agent from guessing. Fewer guesses means fewer wrong edits. Skills Hold the Task Workflows AGENTS.md should not become a long task manual. Workflows like article polishing and git diff review have many details, and they are not relevant to every task. So I keep them in .skills/: .skills/ tech-blog-polish/ SKILL.md git-change-commit-review/ SKILL.mdtech-blog-polish defines how I want technical articles refined: structure, audience, tone, and phrases to avoid. git-change-commit-review defines how to review changed files: which git checks to run, how to separate staged and unstaged changes, when to split commits, and how to write commit messages. AGENTS.md only needs a skills index: ## Shared SkillsProject skills live in `.skills/`.Before handling a request, check whether it matches one of these skill descriptions:- `.skills/tech-blog-polish/SKILL.md` - `.skills/git-change-commit-review/SKILL.md`When a request matches a skill, read that skill's `SKILL.md` and follow it as the source of truth for the task.The agent does not need to read every skill on every turn. It can start from AGENTS.md, then open the matching SKILL.md only when the task calls for it.AGENTS.md is the entry point. .skills/ contains the details. The entry point should stay stable, and the details should evolve independently.Why I Did Not Add .claude/skills or .agents/skills Yet Claude Code and Codex both have their own skill discovery paths: .claude/skills/ .agents/skills/If I wanted to match those defaults exactly, I could expose .skills/ through symlinks or a sync step: .claude/skills -> .skills .agents/skills -> .skillsI am not doing that yet. On Windows, symlinks can require Developer Mode or administrator permissions, and team environments are not always identical. For this repo, explicitly pointing agents to .skills/ from AGENTS.md is stable enough. If native tool skill discovery becomes necessary later, I can add the adapter then. The first priority is keeping the canonical source clear. Commit Rules Belong in the Repo Too During this cleanup, I also made the git workflow explicit: ## Git Workflow- Use the git change review skill when reviewing changed files or proposing commit messages. - Every commit must include both a subject and a body.This small rule matters. Agents can easily create a one-line commit when moving quickly. Once the rule lives in the repo, every review and commit goes back to the same standard. This is also why I want AGENTS.md in git. Repo working rules should be reviewed like code, not scattered across personal tool settings. When Tool-Specific Rules Are Still Useful I am not saying .cursor/rules, .claude/skills, or .agents/skills should never exist. I only add them when the need is real. Use AGENTS.md when the rule applies to the whole repo. Use .skills/<name>/SKILL.md when the rule is a repeatable task workflow. Add .cursor/rules when Cursor needs path-scoped or trigger-specific behavior. Here is a clever trick: even though we keep our repeatable workflows inside the .skills/ directory to prevent rule drift, we can still use Cursor's .cursor/rules/*.mdc as automated triggers (adapters). For example, you can create a lightweight .cursor/rules/polish-trigger.mdc that targets glob: "src/content/posts/**/*.md". Inside this file, instead of repeating your guidelines, write a single instruction:"When writing or editing blog posts, you MUST read and follow the styling and structure guidelines defined in .skills/tech-blog-polish/SKILL.md first."This gives you the best of both worlds. You do not duplicate a single line of your core rules, yet you leverage Cursor's native file-path triggers to automatically load the relevant skill into the Agent's context the moment it opens a post. It is zero-friction automation that preserves the single source of truth. Expose .skills/ through .claude/skills or .agents/skills when native skill discovery becomes important enough to justify the adapter. This keeps tool-specific files late and intentional. Keep the Rule Source Stable AI coding tools will keep changing. Today it is Cursor, Claude Code, and Codex. Tomorrow it may be another agentic IDE. I do not want to rewrite repo rules every time I try a new tool. I want the repo to carry its own working instructions. A new tool should connect to AGENTS.md first, then read .skills/ when it needs task-specific detail. This setup does not use every feature from every tool. It solves the more important problem first: there is only one rule source to maintain.AI coding tools will change, but a repo's working rules should be maintained in one place.
Read More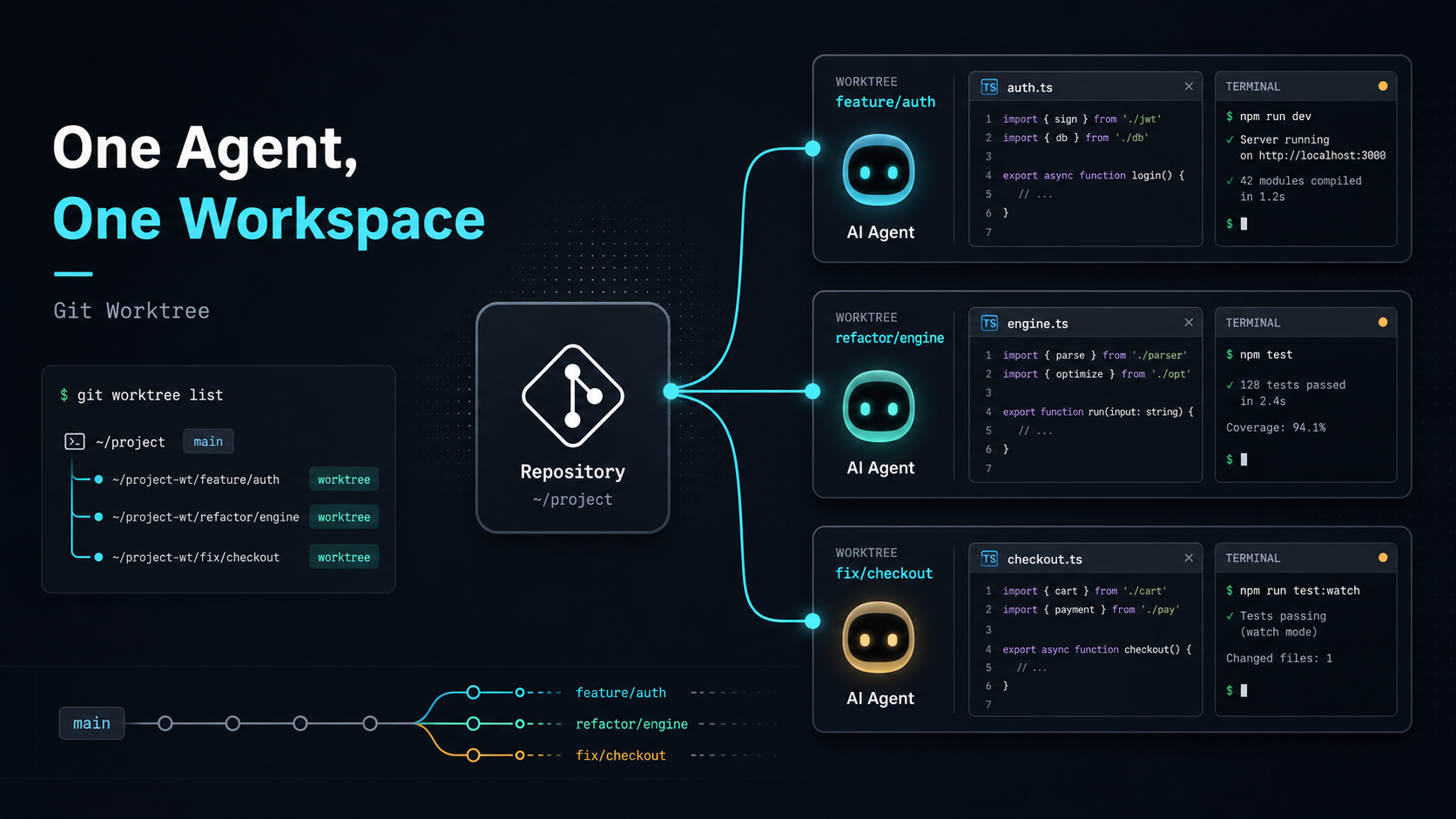
Using AI Coding Agents Well (Part 1): When Branches Are Not Enough for Multi-Agent Work
AI Coding Agents are no longer just tools that help fill in a few lines of code. I personally pay for several AI coding tools, including Cursor, Anthropic Claude Code, and OpenAI Codex. Their interfaces are different, but their capabilities are moving in a similar direction: they can read a project, edit files, run tests, fix errors, and spend time completing a task that has a clear goal. That changed how I use them. I used to keep AI inside the IDE, like an assistant I could call whenever I needed help. Later, I started treating an Agent more like someone who could take a task and work on it for a while. That shift sounds small, but it changes the whole workflow.Once an Agent can work for a long time, we have to manage more than instructions. We also have to manage which copy of the project files it is using.This is Part 1 of my “Using AI Coding Agents Well” series. I want to start with a real problem I ran into: once I began letting an Agent run longer tasks, my old habit of switching Git branches quickly stopped being enough. Starting With Local Edits My first way of working with AI was probably similar to many developers: select a piece of code in the IDE, then ask AI to change that specific part. For example:refactor this function add TypeScript types explain this logic change this API call to another style add testsThis workflow is natural and useful. The unit of work is small, so the risk is easy to control. After AI makes the change, I check the diff, accept it if it looks good, or reject it if it does not. At this stage, the workflow is simple: I know exactly what needs to change, and AI handles that small piece for me. It works like an accelerator for the task already in my hands. When a task only takes a few minutes, this is enough. I still understand the current state of the project, which files changed, and whether I want to keep the result. Long-Running Tasks Changed the Problem Later, while doing Prompt Engineering work, I found a type of task that fits Agents especially well: long-running evaluation. For example:running a batch of prompt evaluation cases comparing outputs from different prompt versions adjusting evaluator or LLM-as-a-judge logic changing prompts based on test results organizing traces or evaluation reportsThese tasks usually do not end after one small edit. The Agent has to read the project, run commands, inspect results, change files, and verify again. A task may grow from a few minutes to half an hour or longer. The problem appears while waiting. If one Agent is running prompt evaluation, I may still want to keep building a new feature, or ask another Agent to fix a bug. My thought at the time was straightforward:Can I let one Agent handle a long-running task in the background while I keep developing on another branch?The obvious answer was to create a new branch. Branches Look Like the Right Tool That is what I tried first. Suppose I have one main project folder: luke-tech-blog/I can create a branch for the long-running task: git checkout -b agent/prompt-evalThen I let the Agent run prompt evaluation on that branch. If you are not familiar with Git, think of a branch as a different path for the same project. One path is for prompt evaluation, another path is for a new feature. That sounds reasonable. Next, I wanted to continue building a new search page: git checkout -b feature/search-pageThat was when the issue became obvious. One project folder can only show the files from one branch at a time. When I switch from agent/prompt-eval to feature/search-page, the files in that folder also switch to another version. That means the Agent running the long task suddenly sees a different set of project files. For a human, this is easy to understand: I just switched branches, so the files changed. For the Agent that is still working, it only sees that the files in its folder suddenly changed. The content it just read, the tests it just ran, and the file it was about to modify may no longer match the new state. Imagine two people sharing the same desk. Agent A is organizing one report. I suddenly replace every document on the desk with documents from another project. Agent A is still sitting there, but the things in front of it have changed.Branches can separate different project paths, but they do not give each Agent its own desk.The Real Problem Is Workspace Separation That experience changed how I understood the problem. The structure I needed was:one project different branches different folders all folders can exist at the same time switching one folder does not affect another AgentIdeally, the project should look like this: luke-tech-blog/ mainluke-tech-blog.prompt-eval/ agent/prompt-evalluke-tech-blog.search-page/ feature/search-pageThen I can assign tasks to different folders: Agent A -> luke-tech-blog.prompt-eval Agent B -> luke-tech-blog.search-pageEach Agent has its own branch and its own folder. The long-running task will not be interrupted when I switch branches elsewhere, and different Agents will not mix their changes in the same place. This is the first practical constraint of multi-Agent collaboration: if tasks can run in parallel, workspaces also need to run in parallel. In the next post, I will introduce the solution I moved to: Git worktree. It lets the same project open different branches in different folders, giving each Agent its own desk. ConclusionOnce an Agent starts handling long-running tasks, each Agent needs a working folder that will not suddenly be replaced by someone else.Using AI Coding Agents Well (Part 2): Give Each Agent Its Own Workspace With Git Worktree
Read More Using AI Coding Agents Well (Part 2): Give Each Agent Its Own Workspace With Git Worktree
In the previous post, I described why branches alone did not solve my multi-Agent workflow. A single working directory keeps everyone tied to the same checkout state.Using AI Coding Agents Well (Part 1): When Branches Are Not Enough for Multi-Agent WorkWhen an Agent is running a long task on one branch, switching the same folder to another branch also changes the files that Agent sees. Its context, test results, and next edits can stop matching the current file state. The solution I moved to was Git worktree. It gives me the structure I actually needed:One repo can open different branches in different folders at the same time.Worktree separates a branch from the single checkout state, so each Agent has its own file workspace.The Worktree Model Git worktree lets one Git repository have multiple working trees. In practice, it lets different branches live in different working directories. It does not clone the repository again. The worktrees still share the same Git object database, while each worktree keeps its own file directory and checkout state. Here is the plain model: project/ mainproject.prompt-eval/ agent/prompt-evalproject.search-page/ feature/search-pageEach folder has its own checkout state. If you edit files in project.search-page, you are not changing the working directory of project.prompt-eval. There is still a cost. Each worktree has real files on disk, so space complexity is roughly O(s), where s is the expanded size of the working tree. Because it shares the Git object database, it is usually lighter than a full clone, but node_modules, build cache, .env, and generated outputs still need to be managed per worktree. Creating or switching a worktree is mostly bounded by the cost of checking out files, roughly O(n), where n is the number of files written to the working directory. In exchange, you get a stable isolation boundary: a long-running Agent task will not be interrupted by another branch checkout. Create an Agent Workspace Assume I am in the main project folder: cd luke-tech-blogTo create a new branch and a new working directory for prompt evaluation, I can run: git worktree add ../luke-tech-blog.prompt-eval -b agent/prompt-evalThis command does two things:Creates a new branch: agent/prompt-eval Creates a new working directory: ../luke-tech-blog.prompt-evalThen I can enter that folder: cd ../luke-tech-blog.prompt-evalFrom that point on, this folder is the workspace for the agent/prompt-eval branch. The original luke-tech-blog folder can stay on main or another branch, without affecting this task. If the branch already exists and I only want to create a working directory for it, I can run: git worktree add ../luke-tech-blog.search-page feature/search-pageThis checks out feature/search-page into ../luke-tech-blog.search-page. Now another Agent can work inside that folder. Manage Worktrees To see which worktrees are currently connected to the repository: git worktree listThe output may look like this: /Users/luke/projects/luke-tech-blog abc1234 [main] /Users/luke/projects/luke-tech-blog.prompt-eval def5678 [agent/prompt-eval] /Users/luke/projects/luke-tech-blog.search-page 789abcd [feature/search-page]After the task is done and the branch is merged, remove the worktree: git worktree remove ../luke-tech-blog.prompt-evalIf you manually delete the folder, Git may still keep a stale worktree record. Clean it up with: git worktree pruneCommand RecapFor daily use, remember three commands first: git worktree add, git worktree list, and git worktree remove.My Multi-Agent Assignment Pattern After adopting Git worktree, my multi-Agent workflow looks like this: git worktree add ../project.prompt-eval -b agent/prompt-eval git worktree add ../project.search-page -b agent/search-page git worktree add ../project.refactor-card -b agent/refactor-cardThen I make the task boundary explicit: You are working in ../project.prompt-eval. Focus on the prompt evaluation task. Do not change UI, deployment config, or unrelated data structures. When finished, report changed files, test results, and risks.Another Agent might get: You are working in ../project.search-page. Implement the frontend search page. Do not modify prompt evaluation files. When finished, run the build and summarize the main diff.The repeatable workflow is:one Agent maps to one clear task one task maps to one branch one branch maps to one worktree each worktree has its own file stateThis lowers review cost. Each worktree ends with one focused diff, and an engineer can use the normal Git workflow to inspect changes, run tests, and decide merge order. The Pain It Solves Git worktree directly solves the problem of shared working-directory state. In a single folder, switching branches changes the whole working directory. You, Agent A, and Agent B are all sharing the same file workspace. If one party switches branches, the others are affected. With worktree, each Agent has its own desk: project/ mainproject.prompt-eval/ agent/prompt-evalproject.search-page/ agent/search-pageproject.refactor-card/ agent/refactor-cardThis gives several practical benefits:long-running tasks are not interrupted when you switch branches elsewhere changes from different Agents do not mix in the same working directory each task produces a cleaner diff for review you can keep a clean main workspace multiple Agents can actually work in parallelWorkflow TakeawayWorktree gives each Agent a stable file workspace while the task is running, even though final merges can still conflict.Humans Coordinate the Boundaries As AI Coding Agents become more capable, the human role moves closer to coordination. I now spend more time on:defining task boundaries choosing which work belongs to an Agent assigning worktrees limiting the allowed edit scope asking the Agent to verify its work reviewing diffs deciding what can be mergedGit worktree helps here because it provides the isolation boundary that the engineering workflow needs. Multiple Agents can work at the same time, while humans keep control over review, verification, and integration. Practical Notes There are a few details to watch for. First, the same branch usually cannot be checked out by two worktrees at the same time. Git does this to prevent the same line of work from being modified in two places. Second, avoid placing worktrees inside the original repo folder. Some tools may search, format, test, or watch those nested worktrees by accident. I prefer a structure like this: projects/ luke-tech-blog/ luke-tech-blog.prompt-eval/ luke-tech-blog.search-page/ luke-tech-blog.refactor-card/Third, each worktree may need its own dependencies. Even if the worktrees share Git objects, files like node_modules, build cache, .env, and generated outputs still need separate handling. Here is a practical tip: if your project uses pnpm (which works wonderfully with Astro projects), its unique global hard-link store design makes running pnpm install in each worktree instantaneous while taking almost zero extra disk space. This completely solves the disk bloating and slow package installation pain points typical of multi-worktree setups. Furthermore, to avoid cluttering your desktop with multiple Cursor or VS Code windows, you can leverage VS Code's Multi-root Workspace feature. Create a simple .code-workspace file in your root and declare your main project folder alongside active worktree folders: { "folders": [ { "path": "luke-tech-blog" }, { "path": "../luke-tech-blog.prompt-eval" }, { "path": "../luke-tech-blog.search-page" } ] }This lets you view and manage files across different isolated workspaces from the sidebar of a single Cursor window, making diff reviews and task coordination extremely convenient. Fourth, worktree isolates workspace state. It does not eliminate merge conflicts. If two Agents edit the same core file, the final merge can still conflict. Worktree prevents them from stepping on each other during execution, but humans still need to design task boundaries first. I prefer assigning these tasks to separate worktrees:long-running evaluation tasks different feature work bug fixes documentation updates test coverage improvements UI and backend work that can be clearly separated small refactors with clear scopeI avoid parallelizing these tasks across multiple Agents:multiple Agents refactoring the same core abstraction multiple Agents changing a shared schema multiple Agents changing global config vague tasks like “optimize the whole project”Conclusion When an AI Coding Agent only edits a small piece of code, one IDE and one working directory are usually enough. Once Agents start running long tasks, or multiple Agents work on different features at the same time, workspace management becomes the first engineering gap to close. Git worktree provides a practical base. Each Agent gets its own branch and folder. Different tasks are isolated at the file level. Humans define tasks, inspect results, and integrate changes. Final TakeawayThe first step toward using AI Coding Agents well is giving each long-running task a stable, verifiable, and disposable workspace.
Read More
PostgreSQL Optimization (Part 1): LIKE vs Regex, which is actually faster?
This post comes from a real performance issue I hit at work. I took a few wrong turns before I understood what was actually slow. This is Part 1: LIKE vs Regex and the I/O vs CPU story. The next two parts go deeper:Part 2: Reading EXPLAIN to see where Seq Scan hides Part 3: Turning tags into an index with Array + GINPart 1: LIKE vs Regex in plain language 1. The setup I inherited ETL-shaped data where many tags were packed into one text field, separated by ;: tag1;tag2;tag3;tag_VIP;tag_inactive So I did the obvious thing: filter with many LIKE conditions. 2. One comment that hit the real issue A senior teammate said:“Merge those LIKE clauses into one Regex. It should run faster.”My first reaction: “If there is no useful index, don’t both approaches still read a lot of rows?” 3. We were not disagreeing, just entering from different angles We were solving the same problem, but from different starting points: I focused on read cost first, while my teammate focused on compute cost first.My focus: I/O costWithout an index, the database often still scans a large part of the table. Teammate’s focus: CPU costMany LIKEs can repeat string checks on the same row.One Regex often reduces that repeated per-row work.A simple analogy:Many LIKEs = reading the same page many times, each time looking for one word. One Regex = reading the page once and checking many words in that pass.4. What I want to pass on If your dataset is small, Regex alone may already feel much better.At larger scale, syntax tweaks are not enough. You need to change how the database reaches the data. ConclusionRegex can reduce CPU work, but if the query still scans most rows, I/O remains the real bottleneck.Part 2 dissects LIKE and Regex with EXPLAIN ANALYZE; Part 3 builds the Array + GIN solution:PostgreSQL Optimization (Part 2): Reading EXPLAIN to see where Seq Scan hides PostgreSQL Optimization (Part 3): Turning tags into an index with Array + GIN
Read More
Want to know more about my technical background?
See About for my background, strengths, and working style.
About me