Luke Kong
專精 Agentic AI Workflow、Multi-Agent(LangChain / LangGraph)、流程自動化(n8n、FastAPI)與 RAG / Text-to-SQL。持有 Azure AI Engineer 與 AWS 雲端架構師認證,專注將商業邏輯轉為可上線的 AI 與自動化系統,並以 LLM-as-a-judge 與 trace 分析確保 production 穩定度。
Posts by Luke Kong
善用 AI Coding Agent(上):當 Branch 不足以支撐多 Agent 協作
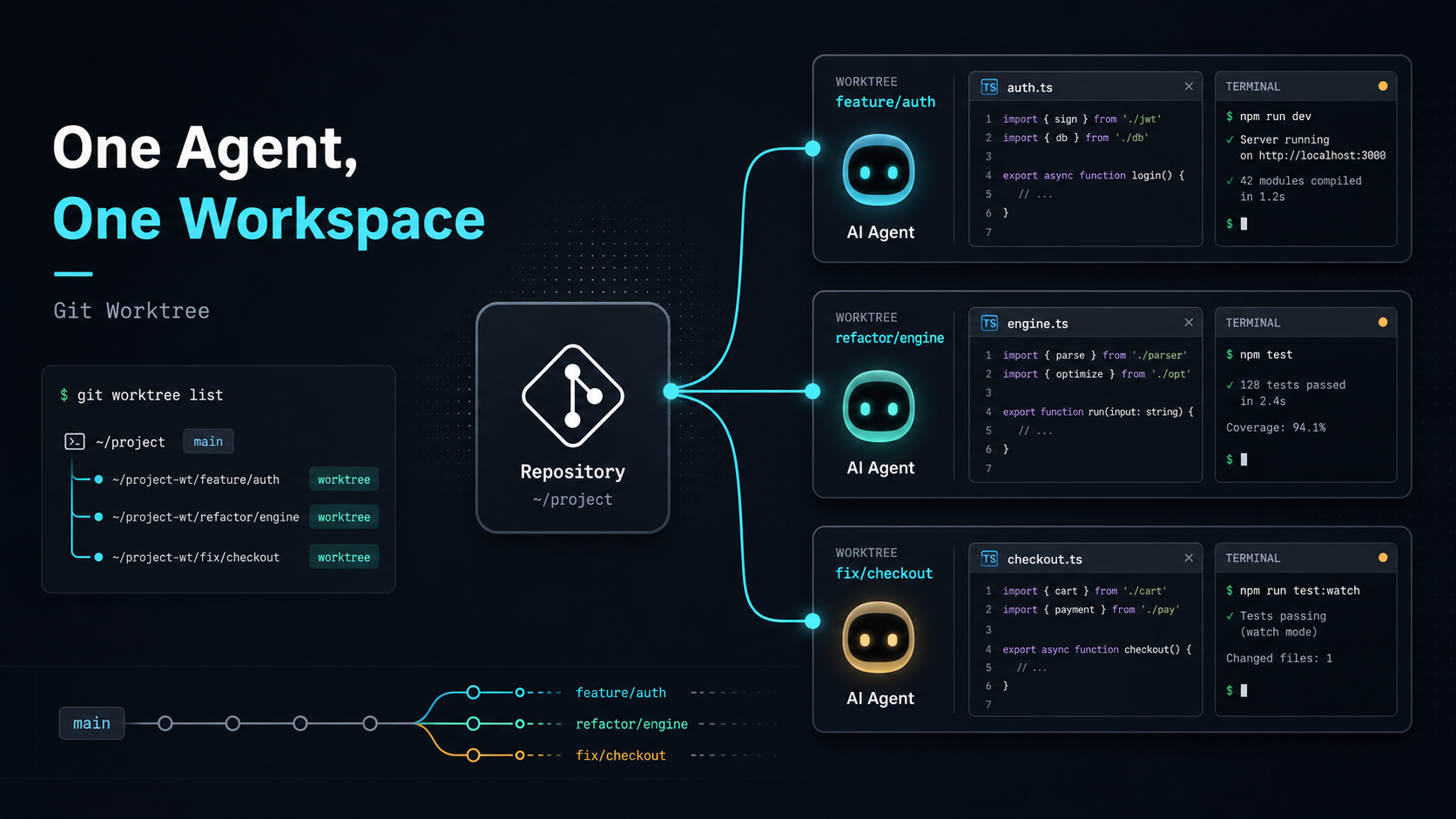
AI Coding Agent 已經不只是「幫忙補程式碼」的工具。 我自己也付費使用多個 AI Coding 工具,包含 Cursor、Anthropic Claude Code、OpenAI Codex。這些工具的介面不同,但能力越來越接近:它們可以讀專案、改檔案、跑測試、修錯,甚至花一段時間完成一個比較完整的任務。 這讓我的使用方式開始改變。以前我把 AI 放在 IDE 裡,像一個隨叫隨到的助手;後來我開始把 Agent 當成可以接任務的人。這個轉變聽起來很小,實際上會改變整個工作流程。當 Agent 可以長時間工作,我們要管理的不只指令,也包含它正在使用哪一份專案檔案。這篇是「善用 AI Coding Agent」系列的上篇。我想先記錄一個實際遇到的問題:當我開始讓 Agent 跑長時間任務,原本靠 Git branch 切換的做法很快就不夠用了。 從局部修改開始 我一開始跟 AI 協作的方式,和很多開發者差不多:在 IDE 裡圈選一段程式碼,然後請 AI 幫我做局部修改。 例如:幫我重構這個 function 幫我補上 TypeScript 型別 幫我解釋這段邏輯 幫我把這個 API call 改成另一種寫法 幫我補測試這種方式非常直覺,也很有效。因為操作單位很小,風險也相對容易控制。AI 改完之後,我看一下 diff,覺得可以就接受,不行就退掉。 這個階段的工作方式很單純:我知道現在要改哪裡,AI 只負責處理我指定的那一小塊。它像是加速器,幫我把手上的工作做快一點。 當任務只有幾分鐘,這樣非常夠用。專案目前在哪個狀態、改了哪些檔案、要不要接受修改,都還在我的掌控範圍內。 長時間任務改變了問題 後來我在做 Prompt Engineering 相關工作時,遇到一類很適合交給 Agent 的任務:長時間評估。 例如:跑一批 prompt 評估案例 比較不同 prompt 版本的輸出品質 調整 evaluator 或 LLM-as-a-judge 的判斷邏輯 根據測試結果反覆修改 prompt 整理 trace 或測試報告這類任務通常不會改一個地方就結束。Agent 需要讀專案、跑指令、看結果、修改檔案,再重新驗證。時間可能從幾分鐘拉長到半小時甚至更久。 問題出現在等待期間。當一個 Agent 正在跑 prompt evaluation,我自己還想繼續開發新功能,或再開另一個 Agent 去修 bug。 當時我的想法很直接:能不能讓一個 Agent 在背景處理長時間任務,同時我繼續在另一個分支上開發?直覺答案是開新 branch。 Branch 看起來可以解決 我一開始也是這樣做的。 假設現在有一個主要專案資料夾: luke-tech-blog/我可以為長時間任務開一個 branch: git checkout -b agent/prompt-eval然後讓 Agent 在這個 branch 上執行 prompt 評估。 如果你不熟 Git,可以先把 branch 想成「同一個專案的不同版本路線」。一條路線用來做 prompt 評估,另一條路線用來開發新功能,聽起來很合理。 接著我想繼續開發新的搜尋頁面: git checkout -b feature/search-page這個瞬間,問題才真的浮出來。 同一個專案資料夾,一次只能顯示一個 branch 的檔案。當我從 agent/prompt-eval 切到 feature/search-page,目前資料夾裡的檔案也會跟著換成另一個版本。 這代表正在執行長時間任務的 Agent,看到的專案檔案被我換掉了。 對人類來說,這件事很好理解:我剛剛切了 branch,所以檔案換了。對正在工作的 Agent 來說,它只知道目前資料夾裡的檔案突然變了。它剛剛讀過的內容、跑過的測試、接下來準備修改的檔案,都可能和新的狀態對不上。 可以把它想像成同一張辦公桌上有兩個人在工作。Agent A 正在整理一份報告,我突然把整張桌子的文件換成另一個專案。Agent A 沒有離開,但它眼前的東西已經不是剛剛那一份了。Branch 可以分開專案的不同版本路線,但沒有替每個 Agent 準備自己的工作桌。問題其實在工作空間 這次經驗讓我重新理解問題。 我需要的結構是:同一個專案 不同 branch 不同資料夾 每個資料夾可以同時存在 我切換其中一個資料夾時,不影響另一個 Agent理想上,我希望專案可以長這樣: luke-tech-blog/ mainluke-tech-blog.prompt-eval/ agent/prompt-evalluke-tech-blog.search-page/ feature/search-page這樣我就可以把不同任務分配到不同目錄: Agent A -> luke-tech-blog.prompt-eval Agent B -> luke-tech-blog.search-page每個 Agent 都有自己的 branch,也有自己的資料夾。長時間任務不會因為我切 branch 被中斷,不同 Agent 的修改也不會混在同一個地方。 這是多 Agent 協作第一個很務實的限制:任務可以平行,工作空間也要能平行。 下一篇,我會接著介紹我後來改用的解法:Git worktree。它可以讓同一個專案在不同資料夾同時打開不同 branch,也讓每個 Agent 有自己的工作桌。 小結當 Agent 開始承接長時間任務,每個 Agent 都需要一個不會被別人突然換掉的工作資料夾。善用 AI Coding Agent(下):用 Git Worktree 替每個 Agent 建立獨立工作區
Read More 善用 AI Coding Agent(下):用 Git Worktree 替每個 Agent 建立獨立工作區
上一篇提到,我一開始想用 branch 解決多 Agent 協作的問題,後來發現單一 working directory 會把所有人綁在同一個 checkout 狀態上。善用 AI Coding Agent(上):當 Branch 不足以支撐多 Agent 協作當一個 Agent 正在某個 branch 上跑長時間任務時,如果我在同一個資料夾切到另一個 branch,Agent 實際看到的檔案也會跟著改變。這會讓它的上下文、測試結果、接下來要修改的檔案互相對不上。 我後來採用的解法是 Git worktree。它剛好提供我要的結構:同一個 repo,可以在不同資料夾同時打開不同 branch。Worktree 把 branch 從單一 checkout 狀態中拆出來,讓每個 Agent 都有自己的檔案現場。Worktree 的模型 Git worktree 可以讓同一個 Git repository 擁有多個 working tree。 簡單說,它可以替不同 branch 建立不同的工作目錄。 它不是重新 clone 一份 repository。這些 worktree 仍然共享同一份 Git 物件資料庫,但每個 worktree 都有自己的檔案目錄與 checkout 狀態。 用白話說: project/ mainproject.prompt-eval/ agent/prompt-evalproject.search-page/ feature/search-page每個目錄都有自己的 checkout 狀態。你在 project.search-page 修改檔案,不會改到 project.prompt-eval 的 working directory。 從成本角度看,worktree 不是免費的。每個 worktree 都會有一份實際檔案,空間複雜度可以粗略視為 O(s),s 是 working tree 展開後的檔案大小。它共享 Git object database,所以通常比完整 clone 省,但 node_modules、build cache、.env、產物目錄仍然各自存在。 建立或切換 worktree 的時間成本主要來自 checkout 檔案,粗略是 O(n),n 是需要寫入工作目錄的檔案數。實務上,這筆成本換來的是更穩定的隔離邊界:長時間任務不會被另一個 branch checkout 打斷。 建立 Agent 專用工作區 假設我現在在主專案目錄: cd luke-tech-blog我想替 prompt evaluation 任務建立一個新的 branch 和工作目錄,可以執行: git worktree add ../luke-tech-blog.prompt-eval -b agent/prompt-eval這個指令做了兩件事:建立一個新的 branch:agent/prompt-eval 建立一個新的工作目錄:../luke-tech-blog.prompt-eval接著我就可以進入那個目錄: cd ../luke-tech-blog.prompt-eval從這一刻開始,這個資料夾就是 agent/prompt-eval branch 的工作空間。 原本的 luke-tech-blog 目錄仍然可以停在 main 或其他 branch,不會被這個任務影響。 如果 branch 已經存在,只是想替它建立一個工作目錄,可以這樣做: git worktree add ../luke-tech-blog.search-page feature/search-page這會把 feature/search-page checkout 到 ../luke-tech-blog.search-page。 之後你就可以讓另一個 Agent 在這個資料夾工作。 管理 Worktree 可以用這個指令查看目前 repository 連到哪些 worktree: git worktree list輸出大概會像這樣: /Users/luke/projects/luke-tech-blog abc1234 [main] /Users/luke/projects/luke-tech-blog.prompt-eval def5678 [agent/prompt-eval] /Users/luke/projects/luke-tech-blog.search-page 789abcd [feature/search-page]任務完成、branch merge 之後,可以移除 worktree: git worktree remove ../luke-tech-blog.prompt-eval如果手動刪掉資料夾,Git 可能還保留著 worktree 紀錄。這時可以執行: git worktree prune這會清掉已經不存在的 worktree 紀錄。 指令小結日常使用先記住三個指令就夠:git worktree add、git worktree list、git worktree remove。我的多 Agent 分配方式 使用 Git worktree 之後,我的多 Agent 工作流會變成這樣: git worktree add ../project.prompt-eval -b agent/prompt-eval git worktree add ../project.search-page -b agent/search-page git worktree add ../project.refactor-card -b agent/refactor-card然後我會把任務講清楚: 你在 ../project.prompt-eval 這個 worktree 工作。 請專注處理 prompt evaluation 任務。 不要修改 UI、部署設定或無關的資料結構。 完成後請回報修改檔案、測試結果與風險。另一個 Agent 則可能是: 你在 ../project.search-page 這個 worktree 工作。 請實作搜尋頁面的前端功能。 不要修改 prompt evaluation 相關檔案。 完成後請執行 build,並整理主要 diff。這裡要建立的是一個可重複的工作流:一個 Agent 對應一個明確任務 一個任務對應一個 branch 一個 branch 對應一個 worktree 每個 worktree 有自己的檔案狀態這個規則可以降低 review 成本。每個 worktree 最後對應一組 diff,工程師可以用一般 Git 流程看變更、跑測試、決定 merge 順序。 它解決的痛點 Git worktree 最直接解決的是檔案工作區被互相影響的問題。 在單一資料夾裡,切 branch 會改變整個 working directory。你、Agent A、Agent B 共用同一個檔案現場;只要其中一方切 branch,其他工作都會受影響。 使用 worktree 之後,每個 Agent 都有自己的桌子: project/ mainproject.prompt-eval/ agent/prompt-evalproject.search-page/ agent/search-pageproject.refactor-card/ agent/refactor-card這帶來幾個好處:長時間任務不會因為你切 branch 被中斷 不同 Agent 的修改不會混在同一個 working directory 每個任務的 diff 更容易 review 可以保留一個乾淨的主工作區 多個 Agent 才真的有機會平行工作工作流小結Worktree 不會讓 merge conflict 消失,但它會讓每個 Agent 在任務執行期間擁有穩定的檔案世界。人類負責協調邊界 AI Coding Agent 變強之後,人類的工作開始往協調者靠近。 我現在更常做這些事:定義任務邊界 選擇適合交給 Agent 的工作 分配不同 worktree 限制修改範圍 要求 Agent 執行驗證 Review diff 決定哪些變更可以 mergeGit worktree 的價值就在這裡。它提供工程流程需要的隔離邊界,讓多個 Agent 可以同時工作,也讓人類保留 review、驗證、整合的控制權。 常見注意事項 使用 worktree 時,有幾個地方要注意。 第一,同一個 branch 通常不能同時被兩個 worktree checkout。這是 Git 的保護機制,避免同一條工作線在兩個地方同時被修改。 第二,不要直接把 worktree 建在原本 repo 的子目錄裡。否則有些工具在搜尋、格式化、跑測試時,可能會把其他 worktree 也掃進去。 我會比較建議這種結構: projects/ luke-tech-blog/ luke-tech-blog.prompt-eval/ luke-tech-blog.search-page/ luke-tech-blog.refactor-card/第三,多個 worktree 可能各自需要安裝 dependencies。即使它們共享 Git 物件,工作目錄裡的 node_modules、build cache、.env 等檔案仍然要自己管理。 這裡推薦一個實戰細節:如果你的專案使用 pnpm(非常適合 Astro 專案),因為其獨特的「全域硬體連結儲存庫(Global Hard-Link Store)」設計,在每個 worktree 目錄執行 pnpm install 不僅能秒級完成,而且幾乎不額外佔用磁碟空間。這能完美解決多 worktree 重複安裝套件又慢又佔空間的痛點。 此外,為了避免在桌面開啟多個 Cursor 或 VS Code 視窗造成的混亂,你可以使用 VS Code 的 Multi-root Workspace 功能。在根目錄建立一個 .code-workspace 檔案,同時引入主目錄與多個活躍的 worktree: { "folders": [ { "path": "luke-tech-blog" }, { "path": "../luke-tech-blog.prompt-eval" }, { "path": "../luke-tech-blog.search-page" } ] }這樣一來,你就可以在同一個 Cursor 視窗的側邊欄中,同時管理與檢視不同工作區的檔案與變更,協調邊界與審查 diff 都會變得極度輕鬆。 第四,worktree 只能隔離工作空間,不能消除 merge conflict。 如果兩個 Agent 同時修改同一個核心檔案,最後合併時還是可能衝突。Worktree 能避免工作期間互相踩檔案狀態,任務邊界仍然要由人類先設計好。 我會優先把這些任務分到不同 worktree:長時間評估任務 不同 feature 的開發 bug fix 文件更新 測試補強 UI 與 backend 可以明確分開的修改 refactor 範圍清楚的小型重構我會避免同時平行丟出這些任務:多個 Agent 同時重構同一個核心 abstraction 多個 Agent 同時修改 shared schema 多個 Agent 同時調整全域設定 任務描述只有「幫我優化整個專案」小結 當 AI Coding Agent 只幫我們改一小段程式碼時,單一 IDE、單一工作目錄通常就夠了。當 Agent 開始執行長時間任務,甚至多個 Agent 同時處理不同 feature,工作空間管理會變成第一個要補上的工程環節。 Git worktree 提供了一個很實用的基礎。每個 Agent 有自己的 branch 與資料夾,不同任務在檔案層級被隔離;人類負責定義任務、檢查結果、整合變更。 結論善用 AI Coding Agent 的第一步,是替每個長時間任務安排穩定、可驗證、可回收的工作空間。
Read More
一份 AGENTS.md,讓多個 AI Coding Agent 共享專案規則(上)
AI coding tools 這幾年幾乎是輪流登場。 Cursor(2023)、Claude Code(2025 年 2 月)、Codex CLI / Codex coding agent(2025 年 4-5 月),以及 Google Antigravity(2025 年 11 月)這類工具持續出現。每個工具都有自己的設定檔、規則格式和使用習慣。剛開始我也會想:是不是每換一個工具,就要重新適應一次?是不是每個工具都要維護一份自己的 instruction? 後來我把問題換了一個角度看。 repo 應該成為穩定的工作入口,工具則負責讀懂 repo 裡的規則。只要專案裡有一份清楚、穩定、可版本控管的工作指引,不管今天打開的是 Cursor、Claude Code、Codex,還是下一個新工具,agent 都應該能快速理解這個專案怎麼跑、怎麼測、文章怎麼寫、commit 怎麼下。AI coding tools 會換,但 repo 的工作規則應該只維護一份。註:本文提到的 Codex 指 OpenAI 在 2025 推出的 Codex CLI / Codex coding agent,不是 2021 年的 OpenAI Codex code generation model。 工具越多,規則越容易漂移 AI coding agent 最怕的情況,不是它不會寫程式,而是它拿到一份過期的專案規則。 這件事通常不是故意發生的。比較常見的情境是:一開始只有 Cursor,所以你寫了 .cursor/rules。後來開始用 Claude Code,又補了一份 CLAUDE.md。再後來想試 Codex,於是多了一份 AGENTS.md。每一份文件剛建立時都很合理,但幾個月後它們開始長得不一樣。 例如:AGENTS.md 說 commit 要有 body CLAUDE.md 還停留在舊的單行 commit 習慣 .cursor/rules 裡的測試指令沒有更新 skills 的內容被複製到多個工具專屬資料夾這種 drift 很難靠記憶補救。人都會忘記更新文件,agent 當然也只能照它讀到的內容做事。當同一個 repo 對不同工具說出不同規則,最後受傷的是開發流程本身。 我的整理方向很簡單:repo 只保留一份 project instructions。工具需要自己的入口時,就讓那個入口變成 adapter。 官方文件其實指向同一個方向 我整理 Claude Code、Codex、Cursor 的官方文件後,發現三個工具雖然格式不同,但可以收斂成同一個架構。 Codex:用 AGENTS.md 當 project instructions Codex 官方文件把 AGENTS.md 當成專案指令的主要入口。這份文件適合放 repo 的固定規則,例如:專案結構 常用指令 coding convention 測試方式 PR / commit 期待Codex 也支援 root AGENTS.md 搭配子目錄的 AGENTS.override.md。如果某個資料夾需要特殊規則,可以把 override 放到那個子目錄,讓越靠近工作目錄的規則有更高優先權。 這個設計很適合放「穩定、全 repo 適用」的內容。它不適合塞進一大段任務細節,因為任務流程會越長越難維護。 Claude Code:用 CLAUDE.md 匯入 AGENTS.md Claude Code 官方預設讀 CLAUDE.md。如果 repo 已經有 AGENTS.md,官方文件建議在 CLAUDE.md 裡用 import: @AGENTS.md這是很重要的小細節。CLAUDE.md 裡只寫 AGENTS.md 可能看起來也像在提醒模型讀檔,但它不是官方 import 語法。用 @AGENTS.md 才能把 Claude Code 的入口降到 adapter 的角色。 最後 repo 裡真正需要維護的 project instructions 還是 AGENTS.md。 Cursor:簡單情境可以讀 root AGENTS.md Cursor 官方主要推薦 .cursor/rules,因為它可以做更細的規則控制,例如 always apply、依檔案路徑套用、agent requested rule 等。 不過 Cursor 也支援 root AGENTS.md 作為簡單 project instructions。對只有一份全專案規則的 repo 來說,這已經足夠。等到專案真的需要針對 src/content/posts/、src/components/、infra/ 套不同規則,再引入 .cursor/rules 也不遲。 我自己的判斷是:先讓 AGENTS.md 承擔共用入口。當規則開始需要分區、分檔、分觸發條件,再讓 Cursor rules 介入。 Google Antigravity:原生支援 AGENTS.md Google 於 2025 年底推出的 Antigravity 是一款以 Agent 為核心的強大開發環境。它原生支援讀取專案根目錄的 AGENTS.md,並以此作為自主任務執行的決策依據。當我們想進一步導入複雜的 Task Workflow 時,它亦可完美讀取在 AGENTS.md 中索引的 .skills/ 目錄,藉此載入對應的任務規則(例如文章潤飾或 Git 審查),使得「單一規則本體」的理想在 Antigravity 中運行得非常流暢。 共用 AGENTS.md 的最小策略 AGENTS.md 很適合回答一個問題:這個 repo 的基本工作方式是什麼? 我會把它控制在短而穩定的範圍: # Agent Instructions## Repository Expectations- Follow the existing project structure and style before introducing new patterns. - Keep shared agent skills in `.skills/`. - Do not duplicate skill files under tool-specific directories.## Commands- Install dependencies: `npm install` - Start dev server: `npm run dev` - Build: `npm run build` - Type check: `npm run check`## Verification- Run `npm run build` after changing Astro, React, styling, or content rendering code. - Run `npm run check` after changing TypeScript or Astro components. - For documentation-only or skill-only changes, no build is required unless behavior changes.這些規則的共同點是穩定。它們不會因為今天用 Claude Code、明天用 Codex 就改變。 最後可以把工具專屬檔案降到 adapter: AGENTS.md # 唯一 project instructions CLAUDE.md # @AGENTS.md .cursor/rules # 只有進階規則需求時才加入這樣 repo 裡真正需要維護的 project instructions 只有 AGENTS.md。Claude Code 透過 CLAUDE.md 匯入它,Cursor 和 Codex 直接讀它。工具可以各自有 adapter,規則本體不要分裂。下一篇我會用這個部落格 repo 當例子,說明我怎麼把 AGENTS.md 和 .skills/ 拆開:AGENTS.md 放穩定入口,.skills/ 放任務流程,讓 Claude Code、Codex、Cursor 都能共用同一套工作規則。一份 AGENTS.md,讓多個 AI Coding Agent 共享專案規則(下)參考資料OpenAI Codex: Custom instructions with AGENTS.md OpenAI Codex: Agent Skills Claude Code: Memory Claude Code: Skills Cursor: Rules Google Developers Blog: Build with Google Antigravity Google Antigravity Official Portal AGENTS.md Guide: Cross-Tool Rules for Antigravity AGENTS.md Official Standard OpenAI: Introducing Codex TechCrunch: Anysphere raises $8M from OpenAI to build an AI-powered IDE TechCrunch: Anthropic launches Claude Code research preview
Read More 一份 AGENTS.md,讓多個 AI Coding Agent 共享專案規則(下)
上一篇先整理了官方文件的共同方向:AGENTS.md 可以成為 repo 的共用 project instructions。這一篇回到我自己的部落格 repo,說明最後實際怎麼放檔案。一份 AGENTS.md,讓多個 AI Coding Agent 共享專案規則(上)我的目標很明確:project instructions 只維護一份 task workflow 只維護一份 工具專屬檔案只做 adapter 團隊共用的內容進 git這樣換工具時不用重寫規則。新的 AI coding agent 只要能讀到 repo 裡的入口,就能快速理解專案。 這個 repo 的最後結構 我最後把 repo 整理成這樣: AGENTS.md CLAUDE.md .skills/ README.md tech-blog-polish/ SKILL.md git-change-commit-review/ SKILL.mdAGENTS.md 是唯一 project instructions。它放所有工具都應該知道的穩定資訊,例如 commands、verification、project structure、git workflow。 CLAUDE.md 只保留一行: @AGENTS.md這樣 Claude Code 會匯入 AGENTS.md。CLAUDE.md 不再複製任何專案規則,也不會和 AGENTS.md drift。 Cursor 這邊,我刪掉原本的 .cursor/rules/skills.mdc。原因很單純:那份檔案和 AGENTS.md 寫的是同一件事。既然 Cursor 可以讀 root AGENTS.md,這個 repo 暫時不需要 .cursor/rules。 AGENTS.md 放 repo 的穩定入口 目前 AGENTS.md 的角色是「讓 agent 進 repo 後先知道工作方式」。 我會放這些內容: # Agent Instructions## Repository Expectations- Follow the existing project structure and style before introducing new patterns. - Keep shared agent skills in `.skills/`. - Do not duplicate skill files under tool-specific directories.## Commands- Install dependencies: `npm install` - Start dev server: `npm run dev` - Build: `npm run build` - Type check: `npm run check`## Verification- Run `npm run build` after changing Astro, React, styling, or content rendering code. - Run `npm run check` after changing TypeScript or Astro components. - For documentation-only or skill-only changes, no build is required unless behavior changes.這些規則每天都會用到,而且不屬於任何單一工具。Codex 讀到它,Claude Code 讀到它,Cursor 讀到它,應該得到同一套結論。 接著再放 repo 結構: ## Project Structure- Blog posts live in `src/content/posts/`. - English posts live in `src/content/posts-en/`. - Shared agent skills live in `.skills/`. - Static assets live in `public/`.這段看起來很普通,但對 agent 很有用。它少猜一次目錄,就少一次亂翻檔案或改錯位置的機會。 Skills 放任務流程 AGENTS.md 不適合放太長的任務流程。像文章潤稿、git diff review 這類流程,細節會很多,也不是每次工作都會用到。 所以我把它們放進 .skills/: .skills/ tech-blog-polish/ SKILL.md git-change-commit-review/ SKILL.mdtech-blog-polish 處理文章潤稿。它會定義文章結構、讀者類型、語氣、要避免的 AI 味句型。 git-change-commit-review 處理 changed files review。它會規定要跑哪些 git checks、怎麼整理 staged / unstaged、怎麼判斷 commit 是否要拆分,以及 commit message 要怎麼寫。 AGENTS.md 只需要保留 skills index: ## Shared SkillsProject skills live in `.skills/`.Before handling a request, check whether it matches one of these skill descriptions:- `.skills/tech-blog-polish/SKILL.md` - `.skills/git-change-commit-review/SKILL.md`When a request matches a skill, read that skill's `SKILL.md` and follow it as the source of truth for the task.這樣 agent 不需要每次都讀完整 skills。它只要先看 AGENTS.md,等任務真的命中某個 skill,再打開對應的 SKILL.md。AGENTS.md 是入口,.skills/ 是細節。入口要穩,細節要能獨立演進。為什麼不直接放 .claude/skills 和 .agents/skills Claude Code 和 Codex 都有各自的 skills discovery 路徑: .claude/skills/ .agents/skills/如果要完全貼合工具預設,可以用 symlink 或同步方式把 .skills/ 暴露到這些路徑: .claude/skills -> .skills .agents/skills -> .skills但我目前先不做這一步。原因是 Windows 上 symlink 可能需要 Developer Mode 或管理員權限,團隊環境不一定一致。對這個 repo 來說,用 AGENTS.md 明確告訴 agent 去讀 .skills/,已經足夠穩定。 等未來真的需要工具原生 skills discovery,再處理 adapter。先把 canonical source 定下來比較重要。 這次調整的 commit 規則 這次整理過程中,我也順手把 git workflow 寫清楚: ## Git Workflow- Use the git change review skill when reviewing changed files or proposing commit messages. - Every commit must include both a subject and a body.這條規則看起來小,但很實用。agent 很容易為了快速完成任務直接下單行 commit。把規則寫進 repo 後,每次 review changed files 或執行 commit,都會回到同一個標準。 這也是我希望 AGENTS.md 進 git 的原因。repo 的工作規則應該像程式碼一樣被 review,而不是散落在每個工具的個人設定裡。 何時才需要工具專屬規則 我現在的選擇不是永遠拒絕 .cursor/rules、.claude/skills 或 .agents/skills。比較好的判斷方式是看需求。 只有全 repo 共用規則時,用 AGENTS.md。 需要任務流程時,用 .skills/<name>/SKILL.md。 需要 Cursor 依檔案路徑自動套用不同規則時,再加入 .cursor/rules。 這裡有一個絕妙的實戰手法:當我們有多個 .skills/ 流程時,雖然為了避免漂移而把內容收攏在 .skills/ 目錄中,但我們仍然可以使用 Cursor 的 .cursor/rules/*.mdc 機制來作為自動觸發(Auto-trigger)轉接器。 例如,你可以建立一個輕量級的 .cursor/rules/polish-trigger.mdc,設定 glob: "src/content/posts/**/*.md"(只要開啟文章就會觸發),而規則內容僅寫上一行:「當撰寫或修改部落格文章時,請務必先閱讀並遵守 .skills/tech-blog-polish/SKILL.md 裡的寫作指南。」這樣做的好處是,我們完全不需要在 Cursor rules 裡重複複製整套寫作規則,但卻能利用 Cursor 原生的檔案監聽,在 Agent 打開文章檔案的瞬間自動將該 Skill 載入為 context。這既能保持 canonical source 的唯一性,又實現了零磨擦的自動化流程。 需要 Claude Code 或 Codex 原生 skills discovery 時,再用 symlink 或同步方式接到 .skills/。 這樣做可以讓 tool-specific adapter 晚一點出現,而且每次出現都有明確理由。 結論:先穩住規則本體 AI coding tools 還會繼續變。今天是 Cursor、Claude Code、Codex,明天可能又多一個新的 agentic IDE。 我不想每換一個工具,就重寫一份 repo 規則。更好的做法是讓 repo 自己帶著工作說明。新的工具進來時,先接到 AGENTS.md;任務流程需要更細,再讀 .skills/。 這套做法沒有一次吃下所有工具功能,但它先解決最重要的問題:規則本體只有一份。AI coding tools 會換,但 repo 的工作規則應該只維護一份。
Read More
PostgreSQL 效能優化(上):LIKE 和 Regex,哪個比較快?
這篇文章是我在工作上真的卡住過的一次效能問題。中間繞了一些路,最後才把真正的瓶頸抓出來。 本篇為上集,先談 LIKE 與 Regex 的抉擇與 I/O/CPU 迷思;接續兩集分別深入:中集:用 EXPLAIN 看見 Seq Scan 的真相 下集:用 Array + GIN 把標籤變成索引上集:當 LIKE 遇上 Regex,到底差在哪? 1. 問題背景(白話版) 我在工作上接了一批 ETL 後的資料。每筆資料裡,很多標籤被塞在同一個欄位,用 ; 串起來,像這樣: tag1;tag2;tag3;tag_VIP;tag_inactive 當我要找特定標籤時,最直覺是寫很多個 LIKE。 2. 同事一句提醒,直接點到問題 同事說:「把多個 LIKE 合成一個 Regex,通常會更快。」 我第一反應是:「沒有索引的話,不是都要整張表一筆一筆看過去嗎?那真的會快多少?」 3. 我們都沒錯,只是看的是不同成本 後來我才搞懂,我們其實切入點不同:我先看讀取成本(I/O),同事先看運算成本(CPU)。我看的是 I/O(讀資料成本)沒有索引時,資料庫通常還是要掃很多資料。這件事不會因為你改成 Regex 就消失。 同事看的是 CPU(運算成本)多個 LIKE 代表同一列要重複比對很多次;合成一個 Regex,通常可把「重複比對」變少。用比喻來說:多個 LIKE 像是同一本書翻很多輪,每次找一個關鍵字。 單一 Regex 像是一輪閱讀就把多個關鍵字一起判斷。4. 這篇上集我最想說的事 如果資料量還小,Regex 可能已經很有感。但資料一大,只換語法通常不夠,最後還是得讓資料庫用不同方式找資料。 結論Regex 可以先減輕 CPU 壓力,但只要查詢還在掃整張表,I/O 依然會是主瓶頸。中集從 EXPLAIN ANALYZE 拆解 LIKE 與 Regex 的真實成本,下集則動手實作 Array + GIN:PostgreSQL 效能優化(中):用 EXPLAIN 看見 Seq Scan 的真相 PostgreSQL 效能優化(下):用 Array + GIN 把標籤變成索引
Read More PostgreSQL 效能優化(中):用 EXPLAIN 看見 Seq Scan 的真相
若你還沒讀過 LIKE/Regex 與 I/O、CPU 兩條戰線,請先看上集;想直接動手做的,可以跳到下集:上集:當 LIKE 遇上 Regex 的觀念碰撞 下集:用 Array + GIN 把標籤變成索引問題升級:Regex 幫了 CPU,但整體還是不夠快 上集的結論提到 Regex 能降低每列字串比對的 CPU 成本,但當資料規模上看千萬、億級時,真正決定延遲與吞吐的是 I/O 與存取路徑,而不是字串語法本身。 這一集要做的就一件事:用 EXPLAIN ANALYZE 把計畫攤開,定位 LIKE / Regex 寫法在哪一步把整張表的 I/O 給綁死了。 確認瓶頸位置之後,下集再動手換存取路徑。關鍵分析:用 EXPLAIN 與複雜度看主導成本註:以下 EXPLAIN 與 SQL 已將 schema、表名、欄位名匿名化處理(例:customers、tag_dictionary、balance 等)。執行統計(rows、loops、Rows Removed、Buffers)來自一份測試資料集的 EXPLAIN ANALYZE 實測,僅作為「結構辨識」範例——關注每個節點長什麼樣、條件擺在哪、有沒有走索引;絕對數字會隨資料量變化,不代表生產環境。用 EXPLAIN ANALYZE 攤開 LIKE 版的計畫,第一個刺眼的訊息是 這條查詢對主表 Seq Scan 了三次。要弄懂為什麼會這樣,必須回到 SQL 語法本身。 從 SQL 找出每一個 Seq Scan 的源頭 把 LIKE 版本的 SQL 簡化、標出每個會碰到主表的位置: WITH product_dict AS ( -- ← 觸發點 1 SELECT DISTINCT product_id, product FROM customers WHERE product <> '' ) SELECT ... FROM customers AS main -- ← 觸發點 2 INNER JOIN product_dict ... WHERE main.segment = 'core' AND lower(main.levels) LIKE '%lv1%' AND lower(main.excluded_levels) NOT LIKE '%ex001%' AND lower(main.excluded_levels) NOT LIKE '%ex022%' AND date_trunc('MONTH', main.etl_date) = date_trunc('MONTH', (SELECT MAX(etl_date) FROM customers)); -- ← 觸發點 3三個觸發點在 SQL 上看起來很無辜:一個 CTE、一個主 FROM、一個 MAX() 子查詢。但對 PostgreSQL 來說,每一個都是「再把表打開讀一次」的指令。對應到 EXPLAIN: -> Aggregate -- 觸發點 3:InitPlan 1 -> Seq Scan on customers Buffers: shared hit=159-> Seq Scan on customers main -- 觸發點 2:主 FROM Filter: segment = 'core' AND lower(levels) ~~ '%lv1%' AND lower(excluded_levels) !~~ '%ex001%' AND lower(excluded_levels) !~~ '%ex022%' AND date_trunc('MONTH', etl_date) = (InitPlan 1).col1 Rows Removed by Filter: 3806 Buffers: shared hit=318-> Seq Scan on customers -- 觸發點 1:CTE 內部 Filter: product <> '' Rows Removed by Filter: 3835 Buffers: shared hit=159四個關鍵訊號:Seq Scan 出現三次:每一次都代表「主表逐列翻一遍」。 每個 Filter 之後的 Rows Removed 幾乎等於該節點吐出的 rows:被讀進來的列絕大多數只是為了被丟掉。 沒有條件被歸到 Index Cond:所有 WHERE 條件都落在 Filter 內,PostgreSQL 找不到任何走索引的入口。 三段 Buffers: shared hit 加總接近主表的全部 page 數:實質上整張表被完整讀了三次。為什麼 LIKE 把每一個掃描都鎖死在 Seq Scan PostgreSQL 預設只會挑 B-tree 索引來規劃查詢(除非你明確替欄位建了 GIN、GiST 等其他類型)。B-tree 是有序樹,能加速的查詢條件只有一種共通特徵:能在樹中定位出起始 key——例如 name = 'Luke' 或 name LIKE 'Lu%',B-tree 都能從特定節點往下走。一旦條件失去這個性質,索引就無從切入。回到三個觸發點的條件:lower(levels) LIKE '%lv1%':前後都是 %,B-tree 沒入口。 lower(excluded_levels) NOT LIKE '%ex001%':NOT LIKE 等於要求對每一列驗證「條件不成立」,索引天生不擅長否定查詢。 date_trunc('MONTH', etl_date) = ...:欄位被函數包住,B-tree 找不到對應的 key(除非建 expression index)。所以三個觸發點全部退回 Seq Scan 的根因只有一個:LIKE 加上「函數包欄位」的寫法根本沒給 PostgreSQL 任何走索引的入口。 改寫成 Regex 之後,SQL 跟 EXPLAIN 變這樣 把兩條 NOT LIKE 改用 Regex(從字典表動態組出 alternation pattern)後,SQL 結構整個換掉: WITH remove_list AS ( -- ← 觸發點 1 SELECT '(^|;|,)(' || REPLACE(string_agg(TRIM(code), '|'), ' ', '') || ')($|;|,)' AS regex_pattern FROM tag_dictionary WHERE kind = 'exclude' AND category IN ('low_marketing', 'private_bank') ) SELECT cluster_list.display_name, main.etl_date, product_list.product, SUM(main.balance)::numeric / COUNT(DISTINCT main.customer_id) AS avg_balance FROM ( SELECT * FROM customers -- ← 觸發點 2 WHERE customer_id <> '' AND segment = 'core' AND etl_date = (SELECT MAX(etl_date) FROM customers) -- ← 觸發點 3 ) AS main LEFT JOIN ( SELECT DISTINCT '%' || lower(code) || '%' AS level_code, display_name FROM tag_dictionary -- ← 觸發點 4 WHERE display_name = 'HVIP' ) AS cluster_list ON main.levels LIKE cluster_list.level_code LEFT JOIN ( SELECT DISTINCT product_id, product FROM customers -- ← 觸發點 5 WHERE customer_id = '' AND product <> '' ) AS product_list ON main.product_id = product_list.product_id CROSS JOIN remove_list WHERE COALESCE(main.excluded_levels, '') !~ remove_list.regex_pattern AND cluster_list.display_name <> '' AND main.product_id <> 0;五個觸發點對應 EXPLAIN 的五個 Seq Scan: -> Aggregate -- 觸發點 3:InitPlan 1(同 LIKE 版) -> Seq Scan on customers Buffers: shared hit=159-> Aggregate -- 觸發點 1:remove_list CTE -> Seq Scan on tag_dictionary Filter: kind = 'exclude' AND category IN ('low_marketing','private_bank') Buffers: shared hit=4-> Seq Scan on tag_dictionary -- 觸發點 4:cluster_list 子查詢 Filter: display_name = 'HVIP' Buffers: shared hit=4-> Seq Scan on customers main -- 觸發點 2:主 FROM Filter: customer_id <> '' AND product_id <> 0 AND segment = 'core' AND etl_date = (InitPlan 1).col1 Rows Removed by Filter: 3308 Buffers: shared hit=318-> Seq Scan on customers -- 觸發點 5:product_list 子查詢 Filter: product <> '' AND customer_id = '' Rows Removed by Filter: 3835 Buffers: shared hit=159主表 customers 還是被 Seq Scan 三次(觸發點 2、3、5),完全沒少;多出來的兩次 Seq Scan 在字典表上(觸發點 1、4)。 更關鍵的是,原本擠在主 Filter: 裡的 LIKE 與 Regex,現在被拆到兩層 Join Filter:: -> Nested Loop -- 套 Regex Join Filter: COALESCE(excluded_levels, '') !~ regex_pattern-> Nested Loop -- 套 LIKE on levels Join Filter: levels ~~ ('%' || lower(code) || '%')LIKE 版 vs Regex 版的結構性對照項目 LIKE 版 Regex 版主表 Seq Scan 次數 3 3字典表 Seq Scan 次數 0 2LIKE / Regex 條件擺在哪 主表的 Filter:(隨 Seq Scan 同時評估) Join Filter:(join 階段才評估)主表 Seq Scan 直接吐出的列 已經套完 LIKE 條件 只套基本條件,字串檢查留待 join 處理兩個結構性結論:主表的 Seq Scan 次數沒變:3 次仍然 3 次。Regex 沒有解決「掃幾次」這件事。 LIKE / Regex 從 Filter 升到 Join Filter:字串檢查被推到 join 階段,主表必須先把所有通過基本條件的列都吐進 join,才開始用 LIKE / Regex 篩。Regex 在 per-row CPU 上理論上更輕(下面解釋為什麼),這個結構性改寫等於把省下的力氣再吐回去。也就是說:SQL 結構決定要掃幾次表,LIKE 或 Regex 只決定每次掃描如何檢查每一列。 為什麼理論上 Regex 能把 CPU 從 $O(N \times M)$ 壓成 $O(N)$ 要理解這個差別,得先補一個概念:狀態機(finite automaton)就是一台「邊讀字元、邊跳狀態」的小機器——給它一個字串,它依序看每一個字元,決定要跳到哪個狀態,最後告訴你「有沒有匹配成功」。Regex 引擎在執行前會把整個 pattern 翻譯成這種結構,常見有兩個變體:DFA(Deterministic Finite Automaton,確定性自動機):每個狀態看到一個字元只有一條轉移路徑,執行快但狀態總數可能爆炸。 NFA(Nondeterministic Finite Automaton,非確定性自動機):每個狀態同一個字元可以有多條轉移路徑,狀態少但執行可能要 backtrack。PostgreSQL 用的是 NFA-based 引擎。對 alternation (ex001|ex022|ex045),編譯出來的狀態機長這樣(簡化): ┌─ 0 → 0 → 1 ✓ ex001 start ─→ e ─→ x ─→ 0 ──────┼─ 2 → 2 ✓ ex022 └─ 4 → 5 ✓ ex045關鍵是共用前綴 ex0 只被處理一次。讀進輸入字串後,每讀一個字元,整台狀態機同時推進所有分支,掃過字串一輪就等於一次判斷完所有替代項。 把這套機制套回查詢:多 LIKE:M 個 pattern 各自獨立、不共用工作,每列要跑 M 次完整字串比對 → CPU ~ $O(N \times M)$ 單 Regex:M 個替代項合併成同一台狀態機,每列只走一次 → CPU ~ $O(N)$省的是「每列的 CPU」,沒有改變「要不要再掃一次表」這件事。 三種寫法的成本主導者 定義符號:N = 主表列數、M = 條件數、K = 命中列數。寫法 每次掃描的 CPU 每次掃描的 I/O多 LIKE ~ $O(N \times M)$ ~ $O(N)$ 全表掃單 Regex ~ $O(N)$ ~ $O(N)$ 全表掃Array + GIN ~ $O(\log N + K)$ 走索引 + 抓命中頁LIKE 與 Regex 只動 CPU 那一欄,I/O 那欄一動沒動;而且 SQL 結構讓查詢碰主表幾次,整體成本就是上表那一欄按次累計。要根本改變每一次掃描的形狀,得讓 Seq Scan 退場、換 Index Scan 上場。 說白了,真正拉開差距的是有沒有讓查詢改走索引那條路。中集小結 到這裡我們已經看清三件事:SQL 結構決定要碰主表幾次(CTE、子查詢、MAX() 各算一次觸發點) LIKE 加上「函數包欄位」讓每一次掃描都鎖死成 Seq Scan:B-tree 只能加速能定位起始 key 的條件,本案三個觸發點全部不符合 Regex 改寫不會減少掃描次數:狀態機只壓 per-row CPU,不改變存取路徑要根本拉開差距,得直接換索引型存取路徑——下集動手做:PostgreSQL 效能優化(下):用 Array + GIN 把標籤變成索引
Read More PostgreSQL 效能優化(下):用 Array + GIN 把標籤變成索引
若你還沒讀過前兩集的問題定位與 EXPLAIN 拆解:上集:當 LIKE 遇上 Regex 的觀念碰撞 中集:用 EXPLAIN 看見 Seq Scan 的真相從觀察到動手:真正要換掉的是存取路徑 中集確認的事實是:LIKE 與 Regex 都讓 PostgreSQL 規劃出全表 Seq Scan,因為 B-tree 索引在 '%xxx%' 條件下找不到入口。要根本改變查詢成本,得做兩件事:改資料模型讓查詢語意能對應到合適的索引型態,建索引讓 PostgreSQL 有索引可走。實作方案:把標籤查詢改成索引友善路徑 我把調校拆成兩步,簡單直接:先改資料型態,再改查詢寫法讓它吃到索引。 A. 資料模型調整(字串 -> 陣列) 先把 'tag1;tag2' 轉為 PostgreSQL 原生 text[],讓查詢語意可以直接映射到陣列運算子: ALTER TABLE customers ADD COLUMN tags_array text[];UPDATE customers SET tags_array = string_to_array(nullif(trim(tags), ''), ';');B. 建立 GIN 倒排索引 CREATE INDEX CONCURRENTLY idx_customers_tags_gin ON customers USING gin (tags_array);查詢改寫為陣列運算(如 &&, @>),讓 PostgreSQL 能走 GIN:tags_array && ARRAY['tag_VIP']::text[]:判斷是否有交集 tags_array @> ARRAY['tag_VIP']::text[]:判斷是否完整包含可帶走的觀念:之後遇到 DB 效能問題都還用得上的基本功 下面這幾個基本功,下次遇到任何資料庫效能問題都會再用到:量測優先於直覺:靠 EXPLAIN ANALYZE 看計畫,永遠比靠經驗或感覺猜瓶頸可靠。 用複雜度語言描述現況:把 N、M、K 這些變數寫出來,才有辦法理性比較不同寫法的代價。 資料模型是性能的天花板:SQL 語法只能在現有結構上做局部優化,要根本拉開差距常常得回頭改欄位設計。 優化要在 plan 上驗證:要看到 Seq Scan 真的換成 Index Scan 才算數,執行時間變短不代表存取路徑改了。結論Regex 的確能先把 CPU 壓力降下來,但資料量一大,真正拉開差距的還是 Array + GIN 這種直接改變查詢路徑的做法。回頭快速複習前兩集:上集:當 LIKE 遇上 Regex 的觀念碰撞 中集:用 EXPLAIN 看見 Seq Scan 的真相
Read More